논문 정리
Salient Object Detection 논문정리 [2019]
hydragon
2021. 7. 13. 23:27
반응형
Salient Object Detection with Pyramid Attention and Salient Edges [CVPR 2019]
- PAGE-Net을 제안
- salient object영역에 더 attention을 주기 위해 essential pyramid attention structure구조를 제안하여 multi-scale saliency information을 잘 뽑게 함
- salient edge detection module을 추가하여 edge영역을 더 잘 refine 함
- 데이터셋은 ECCSD, DUT-OMRON, HKU-IS, PASCAL-S, SOD, DUTS-TE 사용
* 그림 참고용

* Pyramid Attention Module

- 단순하게 입력 feature map을 downsampling 한 후 가각 softmax를 취한 뒤 원래 크기로 resize 함
- 각 softmax 된 확률 맵을 모두 더함
- 원래 feature map의 특정 spatial 정보를 강조하기 위해 hadamard product(element wise product) 진행
- 각각 downsampling 크기에 따라 softmax 결과가 달라지는지 확인 필요
- 수식으로 표현하면 : $Y _ { j } = \frac{ 1 } { N } \sum _ { n=1 } ^ { N } \left ( 1+l _ { j } ^ { n } \right ) X _ { j }$
* Salient Edge Detector

- $I_k, G_k, P_k$는 각각 color image, ground truth saliency map, ground truth salient object boundary map
- 그림에서 $F$가 edge detection module, 단순 CNN 구조
- $F$는 다음과 같이 ground truth salient object boundary map와 L2 loss로 학습되는 단순한 구조
- $L ^ { Edg } \left ( P _ { k } ,F \left ( Y _ { I _ { k } } \right ) \right ) = \left || P _ { k } -F \left ( Y _ { I _ { k } } \right ) \right || _ { 2 } ^ { 2 }$
- $R$에 대한 설명이 안 보여서 확인 필요
- 전체 loss는 $\sum _ { l=1 } ^ { 5 } \left ( L ^ { Sal } \left ( G _ { k } ^ { l } ,R ^ { l } \left ( Y _ { I _ { k } } ^ { l } ,F ^ { l } \left ( Y _ { I _ { k } } ^ { l } \right ) \right ) \right ) +L ^ { Edg } \left ( P _ { k } ^ { l } ,F ^ { l } \left ( Y _ { I _ { k } } ^ { l } \right ) \right ) \right )$
- 아래는 전체 구조

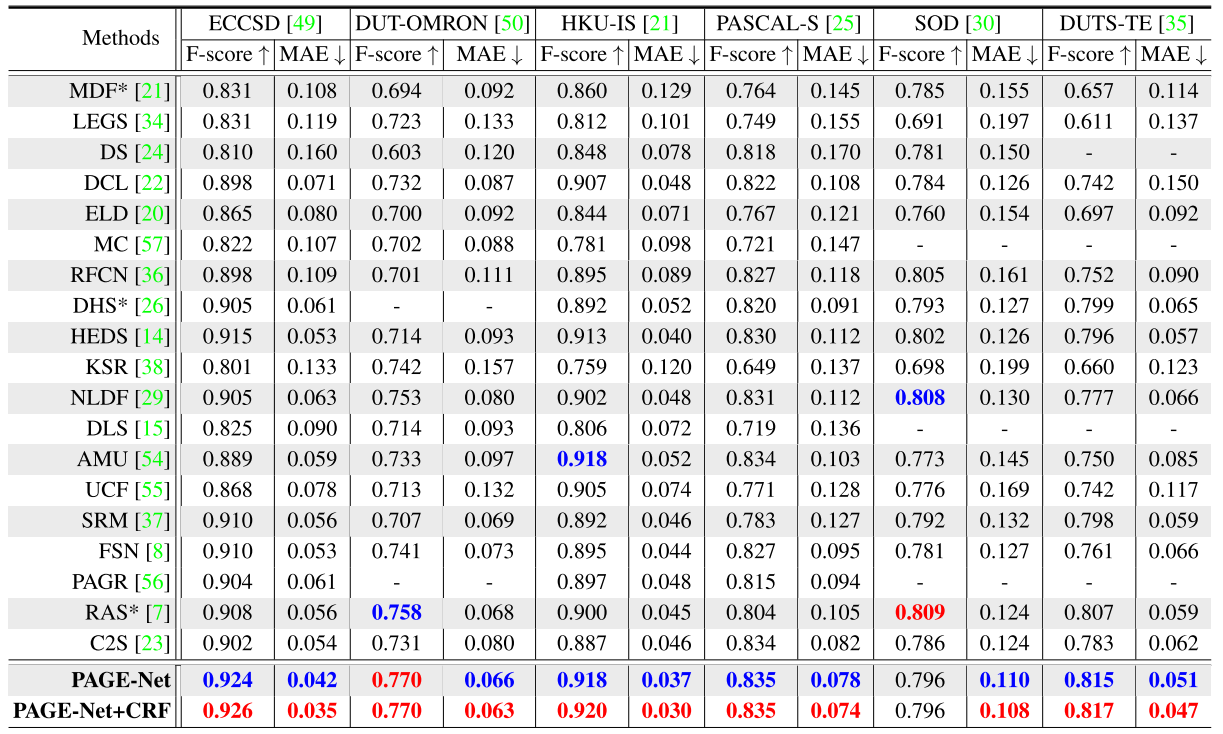
* Result

DeepUSPS: Deep Robust Unsupervised Saliency Prediction With Self-Supervision [NIPS 2019]
- DeepUSPS를 제안
- 기본적으로 GT를 사용하지 않는 Self-Supervised 방식을 사용
- 기존의 handcrafted 방식의 결과를 GT 삼아서 FCN을 학습하는 방식
- 데이터셋은 MSRA-B, ECSSD, DUT, SED2 사용
- 자세한 과정은 아래에 설명

* Enforcing inter-images consistency with image-level loss
- handcrafted 방식으로 결과를 출력하고 특정 threshold로 이진화를 수행
- 이진화된 결과로 FCN을 학습함
- 이때 precision, recall를 이용하는 image-level loss function을 사용하는데, 자세한 사항은 Appendix 참고
* Historical moving averages (MVA)
- 각각의 FCN의 예측값을 moving average 하는 과정
- 모델의 예측값을 $y$, $k$를 epoch이라 하면 MVA는 아래와 같이 업데이트됨
- $MVA \left ( x,p,k \right ) = \left ( 1- \alpha \right ) \ast CRF \left ( y ^ { j } \left ( x,p \right ) \right ) + \alpha \ast MVA \left ( x,p,k-1 \right )$
- 정리하면 예측값에 CRF(Conditional Random Field)를 적용하여 segmentation 맵을 정제하고 moving average로 좀 더 정확한 맵을 생성하는 느낌
- CRF 관련 내용은 추후에 정리 예정
* Incremental pseudo-labels refining via self-supervision
- 위 과정의 반복
- training 중 MVA를 계속 적용하여 MVA 값이 stable 해지는지 확인 (변동이 적은 지?)
- stable 하다면 학습 종료, unstable 하다면 생성된 MVA를 새로운 GT로 계속해서 학습
- stable의 기준점은 확인 필요
* Result


Employing Deep Part-Object Relationships for Salient Object Detection [ICCV 2019]
[paper]
* CapsNet 관련 내용 정리 중
Structured Modeling of Joint Deep Feature and Prediction Refinement for Salient Object Detection [ICCV 2019]
- message-passing 방식의 cascade CRF 아키텍처를 제안함
- feature, prediction 사이의 message-passing을 추가한 구조
- 데이터셋은 MSRA-B, ECSSD, PASCAL-S, DUT-OMRON, HKU-IS, iCoseg 사용


- 구조가 생략된 부분이 많음
- 기본 구조는 이 논문의 구조 (첫번째 그림의 윗줄 점선은 인코더, 두 번째 줄 점선은 디코더 부분으로 추정)
- 결과적으로 CRF 모듈은 다음과 같이 정의됨
- $P \left ( h ^ { l } ,o ^ { l } |I, \Theta \right ) = \frac{ 1 } { Z \left ( I, \Theta \right ) } exp \left \{ -E \left ( h ^ { l } ,o ^ { l } ,I, \Theta \right ) \right \}$
- 이때 $E= \sum _ { i } ^ { } \phi _ { h } \left ( h _ { i } ^ { l } ,f _ { i } ^ { l } \right ) + \sum _ { i } ^ { } \phi _ { o } \left ( s _ { i } ^ { l } ,o _ { i } ^ { l } \right ) + \sum _ { i \neq j } ^ { } \psi _ { h } \left ( h _ { i } ^ { l } ,h _ { j } ^ { l-1 } \right ) + \psi _ { hs } \sum _ { i } ^ { } \phi _ { hs } \left ( h _ { i } ^ { l } ,o _ { i } ^ { l-1 } \right ) + \sum _ { i \neq j } ^ { } \psi _ { o } \left ( o _ { i } ^ { l } ,o _ { j } ^ { l } \right )$
* Result


EGNet: Edge Guidance Network for Salient Object Detection [ICCV 2019]
- salient object의 edge를 잘 살리기 위해 EGNet을 제안함
- salient edge information과 salient object information을 상호 보완적으로 학습 가능함
- 데이터셋은 ECSSD, PASCAL-S, DUT-O, HKU-IS, SOD, DUTS-TE 사용

* Non-local salient edge features extraction (NLSEM)
- edge 정보는 인코더 (VGGNet) 레이어 초반부에서 추출 (해상도가 비교적 높은 영역이라)
- 추출된 edge는 다음과 같이 표현 가능
- $F _ { E } =f \left ( \overline{ C } ^ { \left ( 2 \right ) } ;W _ { T } ^ { \left ( 2 \right ) } \right ) , \overline{ C } ^ { \left ( 2 \right ) } =C ^ { \left ( 2 \right ) } +Up \left ( \phi \left ( Trans \left ( \widehat{ F } ^ { \left ( 6 \right ) } ; \theta \right ) \right ) ;C ^ { \left ( 2 \right ) } \right )$
- $\widehat{ F } ^ { \left ( 6 \right )$ 정보를 사용한 이유는 high-level feature를 추가하기 위함
* Progressive salient object features extraction (PSFEM)
- 디코더 부분으로 Unet과 구조가 비슷함
- 각각 Conv 레이어를 통과 후 feature는 아래와 같이 표현됨
- $\widehat{ F } ^ { \left ( i \right ) } =f \left ( C ^ { \left ( i \right ) } +UpT \left ( \widehat{ F } ^ { \left ( i+1 \right ) } ; \theta ,C ^ { \left ( i \right ) } \right ) ;W _ { T } ^ { \left ( i \right ) } \right )$
- 각 디코더 단계마다 GT랑 loss를 계산
* One-to-one guidance module (O2OGM)
- 단순하게 NLSEM에서 추출된 edge와 salient object 부분을 결합하는 과정
- $G ^ { \left ( i \right ) } =UpT \left ( \widehat{ F } ^ { \left ( i \right ) } ; \theta ,F _ { E } \right ) +F _ { E } , i \in \left [ 3,6 \right ]$
* Result


Selectivity or Invariance: Boundary-aware Salient Object Detection [ICCV 2019]
[paper]
- boundary-aware network를 제안함
- selectivity- invariance 딜레마 (논문 표현 : interior의 feature들은 전체적으로 salient object가 튀어나올 수 있도록 강한 외관의 변화에 따라 변하지 않아야 하며, boundary의 feature들은 눈에 띄는 물체와 배경을 구별할 수 있도록 약간의 외관의 변화로 선택되어야 한다.)
- 전체적인 아이디어는 위 논문과 비슷
- 데이터셋은 ECSSD, DUT-OMRON, PASCAL-S, HKU-IS, DUTS-TE, XPIE 사용

* Boundary Localization
- 단순하게 multi-scale feature로부터 edge 정보를 추출하는 과정
- 수식으로는 $\phi _ { B } \left ( \pi _ { B } \right )$
* Ineterior Perception
- ISD (integrated successive dilation) module을 사용함, 모듈의 구조는 아래 그림 참고
- 수식으로는 $\phi _ { I } \left ( \pi _ { I } \right )$
- 실질적인 디코더 부분, Atrous Spatial Pyramid Pooling (ASPP의 변형 구조인 듯)

* Transition Compensation
- 앞선 두 stream과 달리 GT와 직접적인 학습이 일어나지 않고 Boundary-aware Feature Mosaic 부분에서 간접적으로 학습됨
- 구조는 ISD 모듈과 거의 동일
* Boundary-aware Feature Mosaic
- selectivity와 invariance의 균형을 맞추는 게 목적
- $M _ { B } =Sig \left ( \phi _ { B } \right ) , M _ { I } =Sig \left ( \phi _ { I } \right )$ 이라고 하면 최종 출력은 아래와 같음
- $M= \phi _ { B } \otimes \left ( 1-M _ { I } \right ) \otimes M _ { B } + \phi _ { I } \otimes M _ { I } \otimes \left ( 1-M _ { B } \right ) + \phi _ { T } \otimes \left ( 1-M _ { I } \right ) \otimes \left ( 1-M _ { B } \right )$
* Result


Pyramid Feature Attention Network for Saliency detection [CVPR 2019]
- 최근 방식들이 (예를 들어 위 논문들) multi-scale의 컨볼루션 feture들을 무분별하게 통합하는 방식을 채택한다는 점을 지적
- SIFT에서 영감을 얻은 CPFE(Context-aware Pyramid Feature Extraction)을 제안
- channel-wise attention (CA), spatial attention (SA)의 2가지 attention 적용
- 데이터셋은 DUTS-test, ECSSD, HKU-IS, PASCAL-S, DUT-OMRON 적용


- CPFE는 scale-invariant feature transform (SIFT)에서 영감을 받은 구조
- SIFT는 여기 참고
- 구조적으로 단순하게 각 feature 마다 atrous convolution을 적용한 것이 전부
- 실제 SIFT와 역할이 비슷한지는 확인 필요
- 다른 특징점으로는 CA는 high-level feature에 SA는 low-level feature에 적용
- low-level feature에 spatial 정보가 많이 살아있음을 이용한 듯
반응형