-
Understanding GRU Networks [번역]머신러닝, 딥러닝 공부 2020. 5. 29. 19:06반응형
이 글에서는 정말 매혹적인 유형의 신경망에 대해 매우 간단하고 이해하기 쉬운 설명을 제공하려고 한다. Cho, et al. 2014 년에 GRU (Gated Recurrent Unit)는 표준 recurrent neural network의 vanishing gradient problem를 해결하는 것을 목표로 한다. GRU는 LSTM의 변형으로 간주될 수 있다. 두 가지 모두 비슷하게 설계되고 경우에 따라 동일한 결과를 제공하기 때문이다. Recurrent Neural Networks에 익숙하지 않은 경우 간단한 소개를 읽는 것이 좋다. LSTM에 대한 이해를 돕기 위해 많은 사람들이 Christopher Olah의 글을 추천한다. 이 글은 GRU와 LSTM을 명확히 구분하기 위함이다.
How do GRUs work?
위에서 언급했듯이 GRU는 표준 recurrent neural network의 개선된 버전이다. 그러나 무엇이 그렇게 특별하고 효과적일까?
표준 RNN의 vanishing gradient problem을 해결하기 위해 GRU는 소위 update gate 및 reset gate를 사용한다. 기본적으로 이들은 출력에 전달할 정보를 결정하는 두 개의 벡터이다. 그들에 대한 특별한 점은 정보를 오랜 시간 동안 지우지 않고, 예측과 관련이 없는 정보를 제거하지 않고 오래전에 정보를 유지하도록 훈련시킬 수 있다는 것이다.
이 과정을 수학적으로 설명하기 위해 다음과 같은 recurrent neural network에서 single unit을 검토한다.
Recurrent neural network with Gated Recurrent Unit single GRU의 보다 자세한 버전은 다음과 같다:

Gated Recurrent Unit 먼저, 표기법을 소개한다 :

위의 용어에 익숙하지 않은 경우 "sigmoid", "tanh" 함수 및 "Hadamard product" 연산에 대한 튜토리얼을 보는 것이 좋다.
#1. Update gate
우리는 다음의 수식을 사용하여 시간 단계 t에 대한 update gate z_t를 계산하는 것으로 시작한다.
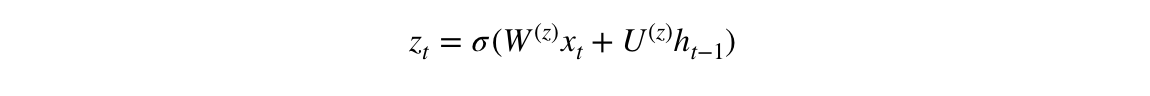
x_t가 network unit에 연결되면 가중치 W(z)가 곱해진다. 이전 t-1 unit에 대한 정보를 보유하고 가중치 U(z)를 곱한 h_(t-1)도 마찬가지이다. 두 결과가 모두 더해지고 sigmoid activation function이 적용되어 0에서 1 사이의 결과를 출력한다. 위 흐름에 따라 다음과 같은 결과를 얻는다.

Update gate는 모델이 과거 정보(이전 time step에서)가 미래에 얼마나 많은 정보를 전달해야 하는지 결정하는 데 도움이 된다. 모델이 과거의 모든 정보를 복사하고 vanishing gradient problem의 위험을 제거할 수 있기 때문에 매우 강력하다. 우리는 나중에 update gate의 사용법을 볼 것이다. 이제 z_t의 공식을 기억하자.
#2. Reset gate
기본적으로 이 gate는 모델에서 사용되어 과거 정보 중 얼마나 많은 정보를 잊어버릴지를 결정한다. 그것을 계산하기 위해 다음 식을 사용한다.
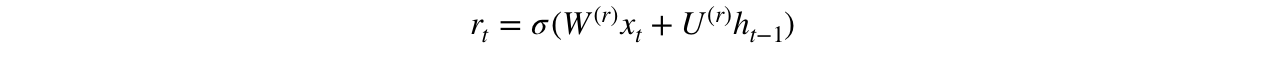
이 공식은 update gate의 수식과 동일하다. 차이는 가중치와 gate의 사용량에 따라 달라진다. 아래 그림은 reset gate의 위치를 보여준다.

이전과 마찬가지로 h_ (t-1) -> 파란색 선 및 x_t -> 자주색 선을 연결하고 해당 가중치를 곱하고 결과를 합산하고 sigmoid 함수를 적용한다.
#3. Current memory content
Gate가 최종 출력에 정확히 어떤 영향을 미치는지 보자. 먼저, reset gate의 사용법부터 시작한다. reset gate를 사용하여 과거의 관련 정보를 저장하는 새로운 memory content를 소개한다. 이는 다음과 같이 계산된다.

-
입력 x_t에 가중치 W를 곱하고 h_(t-1)에 가중치 U를 곱한다.
-
Reset gate r_t와 Uh_(t-1) 사이의 Hadamard (element-wise) 곱을 계산한다. 이전 time step에서 무엇을 제거할지 결정한다.
-
1. 과 2. 의 결과를 더한다.
-
nonlinear activation function tanh를 적용한다.

우리는 h_ (t-1) —> 파랑 선과 r_t —> 주황색 선을 element-wise 곱한 다음 결과 —> 분홍색 선과 입력 x_t —> 자주색 선을 합산한다. 마지막으로 tanh는 h'_t —> 밝은 녹색 선을 생성하는 데 사용된다.
#4. Final memory at current time step
마지막 단계에서 네트워크는 현재 unit에 대한 정보를 보유하고 네트워크로 전달하는 h_t -> 벡터를 계산해야 한다. 이를 위해 update gate가 필요하다. 현재 memory content -> h_ (t-1)에서 수집할 내용 및 이전 단계에서 수집 한 내용을 결정한다.

-
update gate z_t 및 h_ (t-1)에 element-wise 곱셈을 적용한다.
-
(1-z_t) 및 h'_t에 element-wise 곱셈을 적용한다.
-
1.과 2. 의 결과를 더한다.
위의 식을 설명하는 그림은 다음과 같다.

다음으로 z_t —> 녹색 선을 사용하여 1-z_t를 계산하여 h'_t —> 밝은 녹색 선과 결합하여 진한 빨간색 선으로 결과를 생성하는 방법을 확인할 수 있다. z_t는 element-wise 곱셈에서 h_ (t-1) —> 파란색 선과 함께 사용된다. 마지막으로 h_t —> 파란색 선은 밝은 빨간색 선과 어두운 빨간색 선에 해당하는 출력을 합한 결과이다.
이제 GRU가 update 및 reset gate를 사용하여 정보를 저장하고 필터링하는 방법을 확인할 수 있다. 모델이 매번 새로운 입력을 지우지 않고 관련 정보를 유지하고 네트워크의 다음 단계로 전달하기 때문에 vanishing gradient problem를 제거한다. 주의해서 훈련하면 복잡한 시나리오에서도 성능이 매우 뛰어나다.
반응형'머신러닝, 딥러닝 공부' 카테고리의 다른 글
Feature Pyramid Networks (0) 2021.01.05 Non-local Neural Networks (0) 2020.07.04 Understanding LSTM Networks [번역] (0) 2020.05.22 Perceptual Losses for Real-Time Style Transfer and Super-Resolution (0) 2020.05.16 You Only Look Once: Unified, Real-Time Object Detection (0) 2020.03.09 -