-
An Introduction to different Types of Convolutions in Deep Learning [번역]머신러닝, 딥러닝 공부 2020. 2. 27. 23:59반응형
다양한 종류의 convolution과 그 이점에 대해 간략하게 설명하겠다. 단순함을 위해서, 오직 2D convolution에만 초점을 맞추고 있다.
Convolutions
첫째로, 우리는 convolutional 계층을 정의하는 몇 가지 매개변수를 정의할 필요가 있다.

2D convolution using a kernel size of 3, stride of 1 and padding - Kernel Size : 커널 크기는 convolution의 field of view를 정의한다. 2D의 경우 일반적으로 3x3 픽셀이 선택된다.
- Stride : stride는 이미지를 통과할 때 커널의 step size로 정의한다. 기본값은 보통 1이지만 MaxPooling과 유사한 이미지를 다운 샘플링하는 데 2의 stride를 사용할 수 있다.
- Padding : padding은 샘플의 테두리를 처리하는 방법을 정의한다. 패딩 된 convolution은 공간 출력 차원을 입력과 동일하게 유지하는 반면, 커널이 1보다 크면 추가되지 않은 convolution도 일부 경계가 crop 된다.
- Input & Output Channels : convolutional layer는 일정한 수의 입력 채널(I)을 취하여 특정 수의 출력 채널(O)을 계산한다. 그러한 계층에 필요한 매개변수는 I*O*K로 계산할 수 있으며, 여기서 K는 커널을 이루는 수의 개수와 같다.
Dilated Convolutions
(a.k.a. atrous convolutions)
Dilated convolution은 dilation rate(확장률)이라 불리는 convolutional layer에 또 다른 매개변수를 도입한다. 이것은 커널의 값 사이의 간격을 정의한다. dilation rate가 2인 3x3 커널은 5x5 커널과 동일한 시야를 가지며 9개의 파라미터만 사용한다. 5x5 커널을 가지고 모든 두 번째 열과 행을 삭제한다고 상상해 보자.

2D convolution using a 3 kernel with a dilation rate of 2 and no padding 이것은 동일한 계산량으로 더 넓은 field of view를 제공한다. Dilated convolution은 특히 실시간 segmentation 분야에서 인기가 높다. 넓은 field of view가 필요하고 여러 개의 convolution이나 큰 커널을 사용할 여유가 없는 경우 사용한다.
Transposed Convolutions
(a.k.a. deconvolutions or fractionally strided convolutions)
일부 소스는 deconvolution이라는 이름을 사용하는데, deconvolution(convolution의 역과정)이 아니기 때문에 부적절하다. 게다가 deconvolution은 존재하지만, 딥 러닝 분야에서는 흔하지 않다. 실제 deconvolution은 회귀의 과정을 역행한다. 이미지를 하나의 convolutional layer에 입력한다고 상상해 보자. 이제 출력을 black box에 던져버리면 원래의 이미지가 다시 나온다. 이 black box는 deconvolution을 한다. 그것은 convolutional layer가 하는 일의 수학적인 역과정이다.
transposed convolution은 가상의 deconvolutional layer와 동일한 공간 분해능을 생성하기 때문에 다소 유사하다. 하지만, 이 값들에 대해 수행되는 실제 수학적 연산은 다르다. transposed convolutional layer는 정기적인 convolution을 수행하며 공간의 변화를 되돌린다.
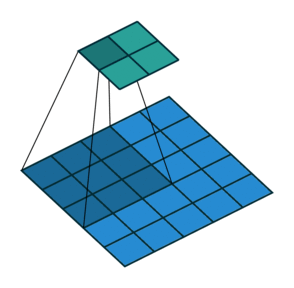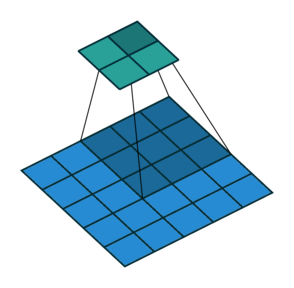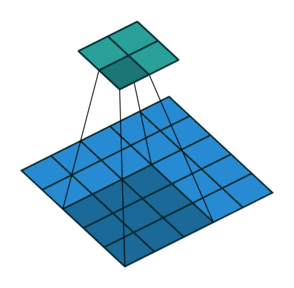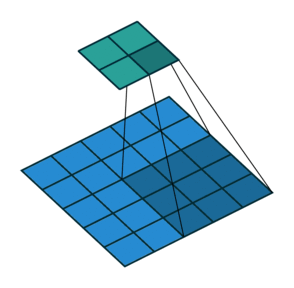
2D convolution with no padding, stride of 2 and kernel of 3 이쯤 되면 상당히 혼란스러울 수 있으므로 구체적인 예를 들어 보자. 5x5의 이미지가 convolutional layer에 입력된다. stride는 2로 설정되며 padding은 제외하고 커널은 3x3이다. 이 경우 2x2 이미지가 생성된다.
만약 우리가 이 과정을 되돌리고 싶다면, 역 수학적 연산이 필요하며, 결국 우리가 입력하는 각각의 한 픽셀에서 9개의 값이 생성될 것이다. 그 후에 출력 이미지를 2의 stride으로 처리한다. 이것이 deconvolution일 것이다.
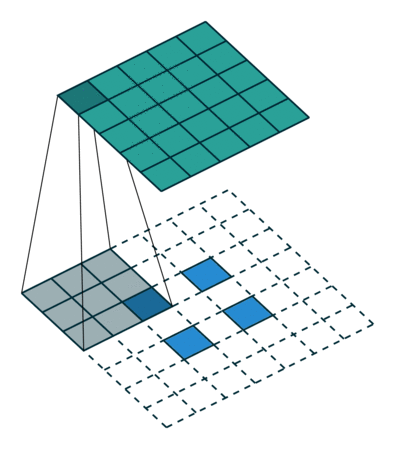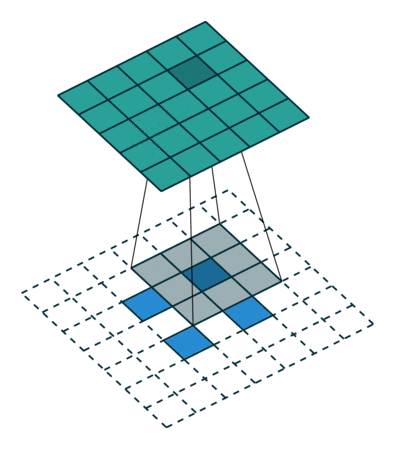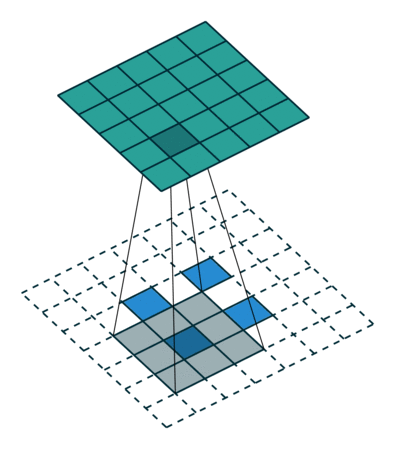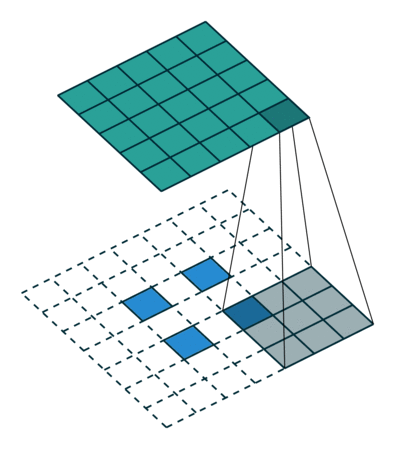
Transposed 2D convolution with no padding, stride of 2 and kernel of 3 transposed convolution은 그렇게 하지 않는다. 단 하나의 공통점은 출력이 5x5 이미지일 뿐이며, 여전히 일반적인 convolution 연산을 수행한다는 점이 다르다. 이를 위해서는 입력에 특별한 padding을 수행해야 한다.
상상할 수 있듯, 이 단계는 위의 과정을 역행하지는 않을 것이다. 적어도 숫자 값과 관련된 것은 아니다.
이것은 단지 이전의 공간적 분해능을 재구성하고, convolution을 수행한다. 이것은 수학적 역과정이 아닐 수도 있지만, Encoder-Decoder architecture에 대해서는 여전히 매우 유용하다. 이런 방법으로 우리는 두 개의 개별적인 과정을 하는 대신에 이미지의 upscaling과 convolution을 결합시킬 수 있다.
Separable Convolutions
분리할 수 있는 컨볼루션에서는 커널 작업을 여러 단계로 나눌 수 있다. convolution을 y = conv(x, k)로 표현해 보자. 여기서 y는 출력 이미지, x는 입력 이미지, k는 커널이다. 또한 k = k1.dot(k2)로 계산된다고 가정해보자. 이것은 k와 2D convolution을 수행하는 대신 k1와 k2로 1D convolution 하는 것과 동일한 결과를 가져오기 때문에 separable convolution이 된다.

Sobel X and Y filters 이미지 처리에서 자주 사용되는 Sobel 커널을 예로 들자. 벡터 [1, 0, -1]과 [1, 2, 1].T를 곱하면 동일한 커널을 얻을 수 있다. 동일 작업을 하기 위해 9개 대신 6개의 파라미터가 필요하다. 이 사례는 Spatial Separable Convolution의 예시이지만, 딥러닝에선 자주 사용되지는 않는다. (참고 : 사실 1xN, Nx1 커널 레이어를 쌓아 Separable convolution과 유사한 것을 만들 수 있다. 이것은 최근 유망한 결과를 보여준 EffNet라는 아키텍쳐에서 사용되었다.)
neural network에서, 우리는 흔히 depthwise separable convolution라고 불리는 것을 사용한다. 이는 채널을 분리하지 않고 spatial convolution을 수행하며, 그 다음에 depthwise convolution을 수행한다. 아래 예를 보면 잘 이해할 수 있다.
16개의 입력 채널과 32개의 출력 채널에 3x3 conolutional layer가 있다고 하자. 구체적으로 16개 채널마다 32개의 3x3 커널이 교차하여 512(16x32)의 feature map이 생성된다. 다음으로 모든 입력 채널에서 1개의 feature map을 병합하여 추가한다. 32번 반복하면 32개의 output 채널을 얻을 수 있다.
동일한 예에서 depthwise separable convolution을 위해 16개의 채널을 각각 1개의 3x3 커널로 통과시켜 16개의 피쳐 맵을 생성한다. 이제 합치기 전에 32개의 1x1 convolution으로 16개의 featuremap을 통과한다. 결과적으로 위에선 4068(16*32*3*3) 매개 변수를 얻는 반면 지금은 656(16*3*3 + 16*32*1*1) 매개변수를 얻는다.
이 예는 depthwise separable convolution(depth multiplier가 1이라고 불리는)것을 구체적으로 구현한 것이다. 이런 layer에서 가장 일반적인 형태이다.
우리는 spatial하고 depthwise한 정보를 나눌 수 있다는 가정하에 이 작업을 한다. Xception 모델의 성능을 보면 이 이론이 효과가 있는 것으로 보인다. depthwise seprable convolution은 매개변수를 효율적으로 사용하기 때문에 모바일 장치에도 사용된다.
반응형'머신러닝, 딥러닝 공부' 카테고리의 다른 글
Multi-Scale Context Aggregation by Dilated Convolutions (0) 2020.03.07 Fully Convolutional Networks for Semantic Segmentation (0) 2020.03.01 Up-sampling with Transposed Convolution [번역] (0) 2020.02.18 Accelerating the Super-Resolution Convolutional Neural Network (0) 2020.02.16 Spatial Transformer Networks (0) 2020.02.08