-
Accelerating the Super-Resolution Convolutional Neural Network머신러닝, 딥러닝 공부 2020. 2. 16. 17:19반응형
Introduction
FSRCNN은 비교적 얕은 네트워크를 가지고 있어 각 구성 요소의 영향에 대해 더 쉽게 알 수 있다. 아래 그림과 같이 이전 SRCNN보다 더 빠르고 성능이 좋다.

SRCNN과 FSRCNN-s를 비교함으로써 FSRCNN-s(소형 모델 버전 FSRCNN)은 PSNR(image quality)이 더 우수하고 43.5 fps로 훨씬 빠르다. SRCNN-Ex(A better SRCNN)와 FSRCNN을 비교함으로써 FSRCNN은 PSNR이 더 우수하고 16.4 fps의 훨씬 짧은 실행 시간을 갖는다. 이 논문에서 다루는 내용은 아래와 같다.
-
Brief Review of SRCNN
-
FSRCNN Network Architecture
-
Explanation of 1×1 Convolution Used in Shrinking and Expanding
-
Explanation of Multiple 3×3 Convolutions in Non-Linear Mapping
-
Ablation Study
-
Results
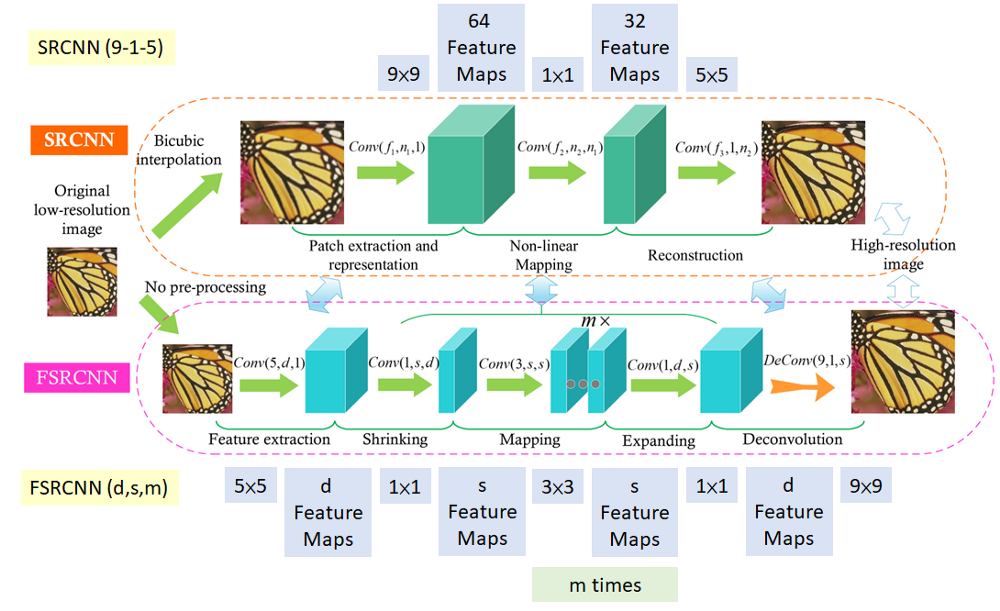
Network Architecture: SRCNN (Top) and FSRCNN (Bottom) 위의 그림은 SRCNN과 FSRCN의 네트워크 아키텍처를 보여준다. 그림에서 Conv(f, n, c)는 n개의 필터와 c개의 입력 채널의 f×f 필터 크기를 가진 convolution을 의미한다.
Brief Review of SRCNN
SRCNN에서 단계는 다음과 같다.
-
Bicubic interpolation은 우선 원하는 분해능으로 upsample 하기 위해 행해진다.
-
그런 다음 9×9, 1×1, 5×5 convolution을 수행하여 영상 화질을 개선한다. 1×1 conv의 경우, 저해상도(LR) 영상 벡터와 고해상도(HR) 영상 벡터의 비선형 매핑에 사용된다.
computation complexity는 다음과 같다.
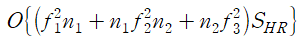
여기서 HR 영상의 크기(S_HR)에 선형적으로 비례한다. HR 영상이 클수록 복잡도가 증가한다.
FSRCNN Network Architecture
FSRCNN에서는 더 많은 convolution이 있는 5가지 주요 단계가 포함된다.
-
Feature Extraction: 이전 SRCNN의 bicubic interpolation은 5×5 conv으로 대체된다.
-
Shrinking: feature map의 수를 d에서 s로 줄이기 위해 1×1 conv가 수행된다. (s<<d)
-
Non-Linear Mapping: 여러 개의 3×3 레이어는 하나의 넓은 레이어를 대체한다.
-
Expanding: 피쳐 맵의 수를 s에서 d로 증가시키기 위해 1×1 conv를 실시한다.
-
Deconvolution: 9×9 필터는 HR 영상을 재구성하는 데 사용된다.
위의 전체 구조를 FSRCNN(d,s,m)이라고 한다. 그리고 computation complexity은 다음과 같다.

따라서 SRCNN보다 훨씬 작게 LR 이미지 크기(S_LR)에 선형적으로 비례한다.
PReLU를 활성화 함수로 사용한다. PReLU는 ReLU보다 더 낫다고 여겨지는 parametric leaky ReLU이다. (다음 글을 참고하자)
Cost function는 standard mean square error(MSE)를 사용한다.
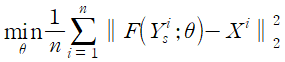
1×1 Convolution Used in Shrinking and Expanding
다음과 같이 1×1 convolution을 사용하지 않고 5×5 convolution을 수행한다고 가정해 보자.
- Without the Use of 1×1 Convolution

Number of operations = (14×14×48)×(5×5×480) = 112.9M
- With the Use of 1×1 Convolution

Number of operations for 1×1 = (14×14×16)×(1×1×480) = 1.5M
Number of operations for 5×5 = (14×14×48)×(5×5×16) = 3.8M
Total number of operations = 1.5M + 3.8M = 5.3M1x1 conv를 사용하는것이 전체 파라미터 수가 압도적으로 작다.
NIN(Network-In-Network)에서는 1×1 conv이 더 많은 비선형성을 가지고 성능을 향상할 것이라고 주장하고, GoogLeNet은 1×1 conv는 성능을 유지하면서 모델 크기를 줄이는 데 도움이 된다고 주장한다. (다음 글을 참고하자)
따라서 1×1은 두 개의 convolution 사이에 사용되어 연결 수(파라미터)를 줄인다. 파라미터를 줄임으로써, 우리는 단지 더 적은 곱셈과 추가 연산만을 필요로 하고, 마지막으로 네트워크의 속도를 높인다. 그래서 FSRCNN이 SRCNN보다 빠른 것이다.
Explanation of Multiple 3×3 Convolutions in Non-Linear Mapping
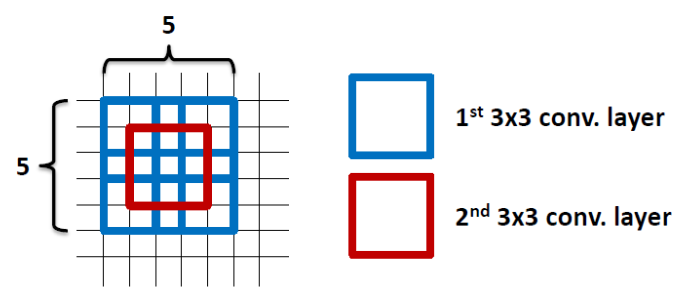
2 layers of 3×3 filters already covered the 5×5 area 3×3 필터 2개를 사용함으로써, 실제로 위의 그림처럼 파라미터의 수가 적은 5×5 영역을 이미 커버한다.
By using 1 layer of 5×5 filter, number of parameters = 5×5=25
By using 2 layers of 3×3 filters, number of parameters = 3×3+3×3=18
Number of parameters is reduced by 28%학습해야 할 매개변수가 적으므로 더 빨리 수렴되며 오버피팅 문제가 줄어든다.
Ablation Study

Ablation Study의 각 단계는 다음과 같다.
-
SRCNN-Ex: 57184 매개 변수를 사용하는 더 나은 버전의 SRCNN.
-
Transition state 1: Deconv를 사용하며, 58976개의 파라미터로 더 큰 PSNR를 가짐.
-
Transition state 2: 중간에 더 많은 convs이 사용되며, 17088개의 파라미터로 더 큰 PSNR을 가짐.
-
FSRCN(56, 12, 4): 필터 크기가 작고 필터 개수가 적으며, 12464개의 파라미터로 PSNR이 더 크다. 이러한 개선은 교육해야 할 매개변수가 적고 수렴이 용이하기 때문이다.
아래는 각 요소들에 대한 기여를 보여준다.

Results
upscaling factor 3으로 91-image dataset를 사용하여 네트워크를 처음부터 훈련한 다음 upscaling factor 2와 4로 General-100 dataset만 추가하여 deconvolutional layer를 fine-tune했다.

All trained on 91-image dataset. 
FSRCNN and FSRCNN-s are trained on 91-image and general-100 dataset. 위의 결과로부터, FSRCNN 과 FSRCNN-s은 upscaling factors 2와 3에 대해 잘 작용한다. 그러나 upscaling factor 4의 경우 FSRCNN과 FSRCNN-s은 SCN 보다 더 성능이 떨어진다.

Lenna image with upscaling factor 3 
Butterfly image with upscaling factor 3 References
반응형'머신러닝, 딥러닝 공부' 카테고리의 다른 글
An Introduction to different Types of Convolutions in Deep Learning [번역] (0) 2020.02.27 Up-sampling with Transposed Convolution [번역] (0) 2020.02.18 Spatial Transformer Networks (0) 2020.02.08 Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization (0) 2020.02.07 Learning Deep Features for Discriminative Localization (0) 2020.02.02 -