-
Knowledge Distillation머신러닝, 딥러닝 공부 2021. 2. 1. 18:39반응형
1. Knowledge Distillation
Knowledge distillation은 NIPS 2014에 제출된 "Distilling the Knowledge in a Neural Network"라는 논문에서 제시된 개념이다. 간단하게 큰 모델(Teacher Network)로부터 증류한 지식을 작은 모델(Student Network)로 transfer 하는 일련의 과정이다. Knowledge distillation은 작은 네트워크가 큰 네트워크와 비슷한 성능을 낼 수 있도록 하는 것이 목적이다.
2. Knowledge Distillation의 구조

https://nervanasystems.github.io/distiller/knowledge_distillation.html $L=\left(1-\alpha\right)L_{CE}\left(\sigma\left(Z_s\right),\ \hat{y}\right)+2\alpha T^2L_{CE}\left(\sigma\left(\frac{Z_s}{T}\right),\sigma\left(\frac{Z_t}{T}\right)\right)$
Knowledge distillation에서 가장 중요한 것은 위의 loss function이다. Loss function의 왼쪽항은 student network의 classification에 대한 loss로, ground truth와 student의 분류 결과와의 차이를 cross entropy loss로 계산한다. (이는 일반적인 classification 학습 방법과 동일하다) 이때 $\sigma\left(\right)$는 softmax 함수이다.
다음으로 오른쪽항은 teacher network와 student network의 classification 결과의 차이에 대한 loss이다. One-hot 인코딩 된 라벨을 사용하는 student loss와 달리 distillation loss는 teacher network의 출력 확률 결과를 label로 사용한다. (이를 Soft label이라 부른다) 두 label의 차이는 아래와 같이 직관적으로 이해된다.
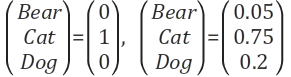
이러한 label의 장점은 입력 이미지에서 고양이와 개가 함께 가지고 있는 특징들이 어느정도 있었기 때문에 dog class score 가 0.2 만큼 나왔다고 생각할 수 있다는 것이다. 하지만 왼쪽과 같이 hard label 로 표현하면 이런 정보가 사라지게 된다. 문제는 다음과 같이

soft label의 다른 값들이 너무 작은 경우이다. 이 경우 다른 class에 대한 정보를 거의 받지 못하기 때문에 위 loss function에서 $T$라는 temperature항이 추가된다. 이 $T$는 원래의 softmax 식 (왼쪽)을 오른쪽으로 바꾸는 효과가 있다.
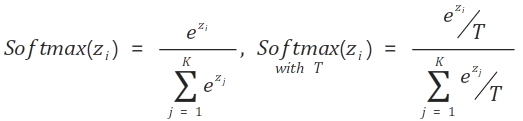
위 수식을 예로 들면

와 같기 때문에 softmax 함수가 입력값이 큰 것은 아주 크게, 작은 것은 아주 작게 만드는 성질을 완화해준다.
reference
반응형'머신러닝, 딥러닝 공부' 카테고리의 다른 글
Salient Object Detection 내용 정리 (0) 2021.08.21 Visual Transformer 구조 (0) 2021.02.08 Feature Pyramid Networks (0) 2021.01.05 Non-local Neural Networks (0) 2020.07.04 Understanding GRU Networks [번역] (0) 2020.05.29